「SEROKU フリーランス(以下、SEROKU)」の中の人をやっている kouki です。
今回は 社内 Kubernetes 実験環境をRancher 1.6から 2.0にアップデートして復活させた話 の中でお話しした「2.0で行ったトラブルシューティング」の「グローバル IP とプライベート IP 2つの足(NIC)を持つサーバを Kubernetes クラスタのネットワークに所属させることができない (Calico ネットワークが確立されない)」という件についてお話させていただきます。
経緯
経緯としては、 Rancher を利用した Kubernetes クラスタに対してインターネットからリーチャビリティを持たせるためにグローバル IP アドレスと社内通信用のプライベート IP 2つの足(NIC)を持つサーバをクラスタに参加させようとしました。
その際に、Kubernetes クラスタ間の通信を行う Canal ネットワークの確立がうまくいかない状況に遭遇しました。
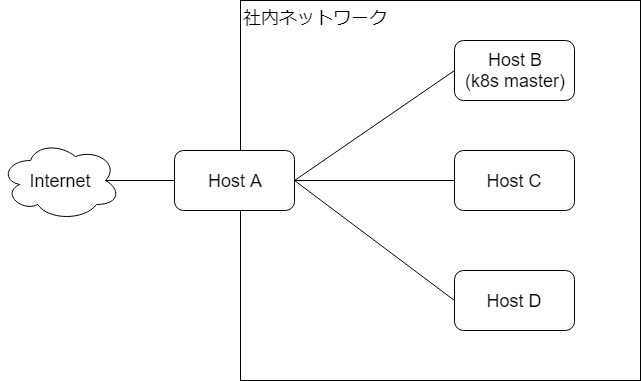
接続イメージとしては以下の通りです。
Host A にグローバル IP アドレスとプライベート IP アドレスを持たせます。
また、正常なケースでは Host A、Host B、Host C、Host D と Kubernetes クラスタを組むための Canal (Calico + flannel) (Canal 以外のネットワークも選択可能です) ネットワークを確立します。
ですが、Host A はインターネットにも接続を持たせたいため、デフォルトゲートウェイを Internet 側(グローバル IP 側) に向ける必要があります。
そうすると、Host B、Host C、Host D との Canal (Calico + flannel) のネットワーク確立に失敗する、という事象に遭遇しました。
直後は「HostA は Host B/C/D にはプライベート IP で到達可能なのに、ネットワーク確立に失敗する理由がまったく分からん」という状態でした。
トラブルシューティング 初動
まずは Host A の中に SSH でログインし、Canal ネットワークを確立しようとするコンテナを調べてみることにしました。
そこで以下のようなログが記録されていました。
$ docker logs k8s_kube-flannel_canal-wtqnx_kube-system_0f6345ce-7b54-11e8-bf7c-525400638f33_18
I0629 14:44:25.191200 1 main.go:487] Using interface with name eth0 and address 192.168.XX.XXX
I0629 14:44:25.191314 1 main.go:504] Defaulting external address to interface address (192.168.XX.XXX)
E0629 14:44:55.192923 1 main.go:231] Failed to create SubnetManager: error retrieving pod spec for 'kube-system/canal-wtqnx': Get https://10.43.0.1:443/api/v1/namespaces/kube-system/pods/canal-wtqnx: dial tcp 10.43.0.1:443: i/o timeoutIP アドレスは伏せてあります。
Host A を追加する際に Kubernetes クラスタ通信用の I/F を指定することができるのですが、無事 192.168.XX.XXX が利用されています。
この点は問題無さそうで、 10.43.0.1:443 への通信がうまくいっていないようでした。
この失敗している状態でルーティングテーブルを参照しても 10.43.0.1 宛のルーティングは登録されている気配がありません。
「どこで通信を曲げているのだろう?」ということがまったくハッキリせず、「一度社内ネットワークにデフォルトゲートウェイを曲げて、その後、グローバルにデフォルトゲートウェイを向けなおす」という workaround を実施し、後日調査することにしました。
トラブルシューティング iptables 編
ふと思いつき、 iptables で通信を曲げているのではないか、ということが思いつきました。そこでまた Host A にログインし、iptable の nat テーブルから調べることにしました。
$ sudo iptables -L -t nat
...
Chain KUBE-SEP-OT4MDINTM57KEHPZ (2 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ all -- * * 192.168.YY.YYY 0.0.0.0/0 /* default/kubernetes:https */
2 120 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/kubernetes:https */ recent: SET name: KUBE-SEP-OT4MDINTM57KEHPZ side: source mask: 255.255.255.255 tcp to:192.168.YY.YYY:6443
...非常に長い出力になるので省略していますが、Kubernetes master である Host B (192.168.YY.YYY) へ通信を曲げている箇所が見つかりました。
このエントリは POSTROUTING として登録されており、おそらく初回起動時にネットワーク設定などを Kubernetes master へ取得しに行っているのだろう、と予想を立てました。
こちらの設定も192.168.YY.YYY へ到達するためには正しいように見えます。
トラブルシューティング 解明編
あと疑う点としては、Kubernetes master へ通信する際に source I/F が加味されているのだろうか、という点でした。
flannel が一番最初に通信するタイミングなども気になったので、 coreos/flannel のソースコードを読むことにしました。
まずソースコードを読むにあたって、当たりを付けたのは、前述した error retrieving pod spec for というメッセージでした。親切に文章として出されているので、おそらくソースコード中に記述されているだろうと、検索をかけてみました。
予想は的中し、メッセージを出しているコードが見つかりました。
pod, err := c.Pods(podNamespace).Get(podName, metav1.GetOptions{})
if err != nil {
return nil, fmt.Errorf("error retrieving pod spec for '%s/%s': %v", podNamespace, podName, err)
}
nodeName = pod.Spec.NodeName
if nodeName == "" {
return nil, fmt.Errorf("node name not present in pod spec '%s/%s'", podNamespace, podName)
}このコードを見ると、おそらく c.Pods(podNamespace).Get(podName, metav1.GetOptions{}) で失敗しているようです。
c の出所を探るため、更に調べると以下のような記述が見つかりました。
c, err := clientset.NewForConfig(cfg)clientset の NewForConfig を利用して、クライアントを作成しているようです。
この clientset は "k8s.io/client-go/kubernetes" を利用しているようでした。
そこからさらに kubernetes/client-go に潜っていきます。
(ここからコードを追う作業は煩雑になるので省略します)
kubernetes/client-go を読むと、 HTTP リクエストを出す際に Source Address の指定はされていないようでした。
また、 kubernetes/client-go を利用している coreos/flannel 側も HTTP リクエストを出すための source I/F を指定しているようには読み取れませんでした。
これらの調査結果から、「Kubernetes master に HTTP でリクエストを行う際に使われるルーティングはデフォルトゲートウェイが用いられる」という裏打ちが取れました。
具体的な workaround
原因が分かれば対処はシンプルで、Kubernetes master (社内のネットワーク) への通信を社内のゲートウェイに向けてあげるだけです。
$ sudo ip route add 10.43.0.1 via 192.168.XX.Xこのコマンドを起動時に実行するように設定するだけでトラブルは発生することはなくなりました。
宛先を 10.43.0.1/32 にしている理由は単純に 10.43.0.1 への通信に失敗していた事実からです。
まとめ
Canal ネットワークのトラブルから、 flannel, client-go へのソースコードに潜ることになるとは思いませんでしたが、go のソースコードリーディングも含めて、良い勉強になりました。
バッドノウハウな気がしなくもないのですが、こういった未知の領域のトラブルをきっかけにノウハウを蓄積することは続けていきたいと思っております。
関連記事
KubernetesをRancher 1.6から2.0 へアップデートした話
DockerfileとKubernetesHelmChartを入れる
Prometheusでスケーラブルな監視基盤を作ってる|概要編

