
こんにちは、 ryosuke です。
今回は、 ドキュメント作成ツールである Sphinx を使って、多言語の文章を作成する際に、困った点とその解決手段について取り上げます。
この記事では、このうちの「困った点」の話をします。
ドキュメント作成と多言語対応
自社開発の Web サービスを提供するにあたり、そのユーザーマニュアルを整備・公開するのも、サービス提供に必要な要素の一つです。
また、日本語のユーザーだけでなく、英語圏のユーザーも獲得したいのであれば、 Web サービスはもちろんのこと、必然的にユーザーマニュアルも多言語対応が必要となるでしょう。
Web で閲覧できる文章を書くためのドキュメント作成ツールは多数存在します。(この blog で使っている wordpress もその一つですね。)
各ツールでのドキュメント執筆方法も (WYSIWYG を使えたり マークアップ言語で記述する、など) 様々です。
それと同様に、多言語対応の方法もツールごとに異なります。
したがって、ツールの選定においては、検討項目として多言語対応の方式も検討項目として、考慮が必要です。
Sphinx の採用例
WESEEK 内のあるプロジェクトでは、ドキュメント作成ツールとして Sphinx を採用しています。
このプロジェクトでのドキュメント作成においては、下記を要件として捉え、ツールを選定しました。
- アプリケーションと同様に git で文章を管理できること
- 完成したドキュメントは Web で閲覧できること
- 日本語と英語の2言語でドキュメントを作成すること
- 言語間でドキュメントの内容に乖離が起きない状態を維持できること
上記要件を念頭に複数のツールを検討した結果、 Sphinx を採用しました。
Sphinx には以下のような特徴があります。
- 代表的なドキュメント作成ツールの1つ
- reStructuredText(reST) という マークアップ言語で文章を記述する
- HTML や PDF など、いくつかの形式でドキュメントの出力が可能
- ドキュメントの国際化(i18n)に対応
i18n 方式の比較
Sphinx は i18n 対応において「翻訳方式」といえる機構を備えているのが特徴です。
reST で書いた文章を「原文」として扱い、その原文中の各単語や段落に対して訳を定義する方式です。
これとは異なる方式として、単純に複数言語分の原稿を取り扱う方式があります。
この方式のわかりやすい例が、GROWI のドキュメントサイトである GROWI Docs です。
ドキュメント作成ツールに VuePress を採用しています。
VuePress の Guide に記載の Internationalization や growi-docs のソースコードを眺めてみるとイメージがつきやすいと思います。
この方式の場合、言語毎に別々の(Markdown で書かれた)原稿ファイルが、各言語用のディレクトリを分けて配置してあるだけです。
したがって、あるページについて、日本語版と英語版の2つを用意したければ、各言語で記述された Markdown ファイルを用意し、各言語用のディレクトリにそれぞれ配置するだけです。
この方式は実にシンプルなので、理解しやすくとっかかり易いと言えるでしょう。
その反面、そのツールだけの機能では、各言語での内容の乖離がある事に気付きにくいという面もあります。
例えば、サービスに新機能を追加したので、既存の日本語用 markdown ファイルに文章を追加したとします。
このとき、英語の markdown ファイルも同様に文章を追加することを忘れた場合、日本語には記載があるが、英語にはないという不一致が発生します。
この不一致が起きていることを機械的に判断するのは困難です。
したがって、人手による2言語間の内容の一致状況を、ていねいに判断するという活動の維持が必要です。
一方で翻訳方式の場合、原文に文章を追加した時点では、翻訳文がない状態になりますから、この状態のままで英文のドキュメントを出力すると、追加した部分だけ翻訳されずに原文(日本語)が表示されます。
このような挙動をするので、(適切に翻訳はされていないものの)2言語間で内容の乖離が起きることはなくなります。
また、翻訳文章を読めば、唐突に別言語の文章が登場する状態になっているので、翻訳が不足している箇所も特定しやすく、翻訳忘れも是正しやすいのが利点です。
こういった方式の特徴について検討した結果、多言語間での内容の乖離が起きない状態の維持を重視し、翻訳方式を採用している Sphinx を採用しました。
Sphinx での i18n 対応の概要
では Sphinx ではどのようにして多言語の文章を作成するのでしょうか?
Sphinx の公式サイト でも詳細な説明がありますが、ここでは、 Sphinx で i18n 対応をする際の作業の大筋の流れや、必要な file の前提知識を記載します。
(後に紹介する、 i18n 対応での課題を理解するために知っておく必要がある知識です)
原文の作成
まず、原文となるドキュメントを作成します。 Sphinx の場合 reST で記述します。
たとえば、下記のような内容の sample.rst ファイルを作成します。
* これはリストの1つ目です
* これはリストの2つ目です
* これはリストの3つ目ですこの原文を元に HTML に build したファイルを出力する場合、以下のコマンドを実行します。
sphinx-build -b html sourcedir builddirこのコマンドを実行することで、 sample.rst に記述した原文から HTML ファイルが出力されます。
翻訳ファイルの生成
次に翻訳された HTML ファイルを出力したい場合は、以下のように追加の作業が必要です。
まず、翻訳対象の文字列を原文から抽出します。
そのために以下のコマンドを実行します。
sphinx-build -b gettext sourcedir builddirすると、 sample.pot というファイルが生成されます。
これを POT ファイルと呼びます。
このファイルは以下のような内容です。1
#: sample.rst:1
msgid "これはリストの1つ目です"
msgstr ""
#: sample.rst:3
msgid "これはリストの2つ目です"
msgstr ""
#: sample.rst:5
msgid "これはリストの3つ目です"
msgstr ""これは、翻訳対象となる文字列を列挙するファイルです。
このうちの msgid と書かれている部分に記述されている文字列が「翻訳対象の文字列」と扱われます。
先ほどの sphinx-build -b gettext sourcedir builddir というコマンドを実行することで、作成済みの reST ファイルの全ての文章を翻訳対象として自動的に POT ファイルが生成されます。
続いて、各翻訳先言語ごとに訳を記述するファイルを生成します。
例えば英語の訳を記述する場合、下記のようなコマンドを実行します。
sphinx-intl update -p builddir -l enすると、 locale/en/LC_MESSAGES ディレクトリに sample.po というファイルが生成されます。
これを PO ファイルと呼びます。
このファイルは以下のような内容です。1
#: sample.rst:1
msgid "これはリストの1つ目です"
msgstr ""
#: sample.rst:3
msgid "これはリストの2つ目です"
msgstr ""
#: sample.rst:5
msgid "これはリストの3つ目です"
msgstr ""先ほど生成した POT ファイルとほとんど変わらない内容です。
PO ファイルは POT ファイルを元に生成されるファイルで、まだ訳が1つもない状態では POT ファイルと差がありません。
ただし、 PO ファイルと POT ファイルは役割が異なります。
PO ファイルは各「翻訳対象の文字列」を具体的にどう翻訳するのか記述します。
各 msgid の直下にある msgstr 部分を編集し、訳を記述します。
例えば、以下のように記述します。
#: sample.rst:1
msgid "これはリストの1つ目です"
msgstr "This is first line of list."
#: sample.rst:3
msgid "これはリストの2つ目です"
msgstr "This is second line of list."
#: sample.rst:5
msgid "これはリストの3つ目です"
msgstr "This is third line of list."これで翻訳作業は終了です。
翻訳した文章の出力
最後に、訳が適用された HTML ファイルを出力するには以下のコマンドを実行します。
sphinx-build -b html sourcedir builddir -D language=enすると適切に翻訳された HTML ファイルが出力されます。
原文の修正と翻訳の修正
なお、原文を加筆・修正などした場合は、 POT ファイルを再生成し、 msgid のリストを最新化し、それを生成済みの PO ファイルに反映させる必要があります。
これを行うのは簡単で、原文修正後に再び以下のコマンドを実行するだけです。
sphinx-build -b gettext sourcedir builddir
sphinx-intl update -p builddir -l enすると、既存の PO ファイルに新たな msgid と空の msgstr が追加されます。
この空の msgstr 部分に適切な訳を記述することで、原文に変更を加えた場合にも新たな訳を設定できます。
翻訳作業時の課題
さて、このような方法で i18n 化できる Sphinx ですが、翻訳作業を進めるにつれ、いくつかの課題が見えてきました。
その課題を紹介します。
reference による大量の差分
PO ファイルには、 msgid に書かれている原文がどのファイルの何行目に登場するのか表現できる、 「reference」という記述があります。
#: ../../source/some_namespace/content.rst:3
msgid "今日は晴れです。"
msgstr "Today is sunny."#: で始まる行で、 行末の数字の直前にある : の手前までが原文の filepath で、その後の数字は原文の登場する行番号を示しています。
上記の例だと「今日は晴れです。 という原文は、 ../../source/some_namespace/content.rst ファイルの 3行目にある」という意味になります。
msgid の文字列だけでは前後の文脈が分からないので、翻訳困難な場合がありますが、 reference の解釈に対応したエディタを使うことで、翻訳者は原文に簡単にアクセスでき、前後の文章を確認しながらよりよい訳文を検討する助けになります。
この reference ですが、原稿が更新され、原文が登場する行番号が変われば、更新されます。
たとえば、すでに数行ほどの文章が書かれた、下記のような reST ファイルと PO ファイルがあったとします。
1行目の文章です。
3行目の文章です。
5行目の文章です。#: ../../source/some_namespace/content.rst:1
msgid "1行目の文章です。"
msgstr "This is a paragraph on first line."
#: ../../source/some_namespace/content.rst:3
msgid "3行目の文章です。"
msgstr "This is a paragraph on third line."
#: ../../source/some_namespace/content.rst:5
msgid "5行目の文章です。"
msgstr "This is a paragraph on fifth line."この reST ファイルの3行目に新たな文章を追加したとします。
1行目の文章です。
後から追記した文章です。
3行目の文章です。
5行目の文章です。この時、 PO ファイルを再生成すると、下記のように元々3行目以降にあった全ての原文の reference が更新されます。
#: ../../source/some_namespace/content.rst:1
msgid "1行目の文章です。"
msgstr "This is a paragraph on first line."
#: ../../source/some_namespace/content.rst:3
msgid "後から追記した文章です。"
msgstr "This is a paragraph that was added later."
#: ../../source/some_namespace/content.rst:5
msgid "3行目の文章です。"
msgstr "This is a paragraph on third line."
#: ../../source/some_namespace/content.rst:7
msgid "5行目の文章です。"
msgstr "This is a paragraph on fifth line."こうして完成した PO ファイルを git commit し、 Pull Request で差分を見ると、下記のような差分として表示されます。
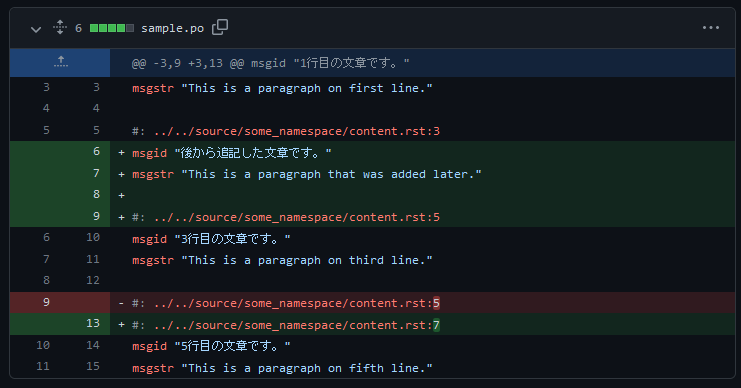
このように、差分として表示される箇所が膨れ上がってしまい、本質的な差分を認識するには、注意深く見比べるほか手段がありません。
文の自動改行による大量の差分
PO ファイルの msgid および msgstr の値は、複数行に分割して記述できます。
つまり、以下の2つの例は完全に同じ内容と解釈されます。
msgid "今日は晴れです。明日は曇りです。明後日は雨の可能性がありますが、現時点では降水確率は低めの予報です。"
msgstr "Today is sunny. Tomorrow will be cloudy. The day after tomorrow there is a chance of rain, but at this time the chance of precipitation is forecast to be low."msgid ""
"今日は晴れです。明日は曇りです。"
"明後日は雨の可能性がありますが、現時点では降水確率は低めの予報です。"
msgstr ""
"Today is sunny. Tomorrow will be cloudy. The day after tomorrow "
"there is a chance of rain, but at this time the chance of "
"precipitation is forecast to be low."この仕様自体に問題はありません。
問題は、 reST ファイルから PO ファイルを生成するときに、文章の長さによっては msgid と msgstr の値が自動的に複数行に分割(整形)されることです。
この挙動は、例えば reST ファイルを以下のように修正した場合に、顕著に表れます。
-今日は晴れです。明日は曇りです。明後日は雨の可能性がありますが、現時点では降水確率は低めの予報です。
+今日は晴れです。明日は曇りです。明後日は雨の可能性があります。その後、PO file に原文の更新を反映すると、以下のような差分が発生します。
こちらが修正前で、
msgid ""
"今日は晴れです。明日は曇りです。"
"明後日は雨の可能性がありますが、現時点では降水確率は低めの予報です。"
msgstr "Today is sunny. Tomorrow will be cloudy. The day after tomorrow there is a chance of rain, but at this time the chance of precipitation is forecast to be low."こちらが修正後です。
msgid "今日は晴れです。明日は曇りです。明後日は雨の可能性があります。"
msgstr ""
"Today is sunny. Tomorrow will be cloudy. The day after tomorrow "
"there is a chance of rain, but at this time the chance of "
"precipitation is forecast to be low."まず、 msgid は、原文が短くなった影響で、複数行に分割されていた箇所が1行にまとめられます。
したがって、本来であれば削除された文字列部分だけ差分ハイライトされることが期待できるにもかかわらず、記述行が移動した分の差分まで現れてしまいます。
さらに、 msgstr も PO ファイルの更新時に自動的に行分割されます。
従って、過去に訳を msgstr に1行に記載していた場合、その値の長さによっては複数行に分割されてしまいます。
このように修正された msgstr を、最新の msgid にあわせて正しい訳に修正すると、下記のようになります。
msgid ""
"今日は晴れです。明日は曇りです。明後日は雨の可能性があります。"
msgstr ""
"Today is sunny. Tomorrow will be cloudy. The day after tomorrow "
"there is a chance of rain."こうして完成した PO ファイルを git commit し、 Pull Request で差分を見ると、下記のような差分として表示されます。

このように、差分として表示される箇所が膨れ上がってしまい、本質的にどのような差分が生じたのかを認知するには、注意深く見比べなければなりません。
翻訳漏れの検知機構不足
翻訳方式の i18n 機構を採用することのメリットに、「原文の変更に訳文が追従しやすい」という点があることを話しました。
しかし、 Sphinx では訳文がない原文があったとしても、警告などの発生なしに翻訳済みの HTML を出力できてしまいます。(すでに説明したとおり、訳がない文章は原文が表示されます。)
Sphinx の設定項目などを調査しましたが、この挙動の変更はできないようです。
したがって、翻訳の網羅性を担保したい場合であっても、「原文の変更に追従していない訳文があったら build エラーにする」などの対応が取れません。
トラブル発生
Sphinx を採用したプロジェクトでは、上記で紹介した課題は、文章作成を開始してから早い段階で認識していましたが、 「Sphinx の仕様」として特段に課題点の改善をすることなく次々と文章作成を進めていました。
一見、順調に進み「課題はあるが大した問題にはならなかった」と思えましたが、ある日突然問題が発覚します。
「過去に訳したはずの文章が訳されずに掲載されている箇所がある」ことが判明したのです。
そのことに気付いたのも偶然でした。
原因は、別の文章の翻訳作業中に、該当の翻訳を「もう使用していない」と誤った認識で削除してしまったことでした。
本来ならば、 CI などによる機械的なチェックやレビューによって問題があることに気付くことが期待されます。
しかし、(原文と比べて翻訳が漏れている点の)機械的なチェックも不足していましたし、人の目によるレビューも「無用な差分が多い」ことによって、本質的な差分を見落とす(目が滑る)状況となり、必要な訳を削除してしまったことに気づけなかったのです。
次回予告
次回は、遂に問題を引き起こした課題に対し、我々のとった改善手段について紹介します。

