
この記事は、2021/12/23 に行った WESEEK Tech Conference #16 の内容をまとめたものです。
第16回目のテーマは「激白!GROWI.cloudの可用性向上の取り組み」
顧客に何らかのサービスを提供する上で、日常的なサービス可用性の維持・向上に関する業務は必須課題となります。
本発表では、可用性維持・向上に必要な項目を挙げつつ、弊社が実際に提供しているサービスである GROWI.cloud での実施例をご紹介しました。
目次
GROWI.cloud の現状の運用規模
本発表時(2021/12/23 時点)の、GROWI.cloud の規模を示すデータをご紹介しました。
- 総ノード数: 56
- ユーザアプリ数
- GROWI: 318
- HackMD: 111
- Keycloak: 15
- 可用性(SLI/過去1か月)
- 通常ノード上の GROWI: 99.995%
- 全ノード上の GROWI: 99.846%
アジェンダ
- サービス運営の上で必要な監視項目とは
- SRE の考え方から、本当に監視すべき項目を設定する
- サービスの可用性を計測・可視化する手法
- 1. を実現するために必要な情報を揃える手段を実装する
- 可用性を維持/向上するために必要な取り組み
- 1./2. を用意した上で、実際にどのような取り組みを実施しているか
1章: サービス運営の上で必要な監視項目とは
監視項目
みなさん、運用しているサービスの監視をどのように実施していますか?
一言に監視項目と言えども、以下のように様々な監視ポイントが思い浮かぶと思います。
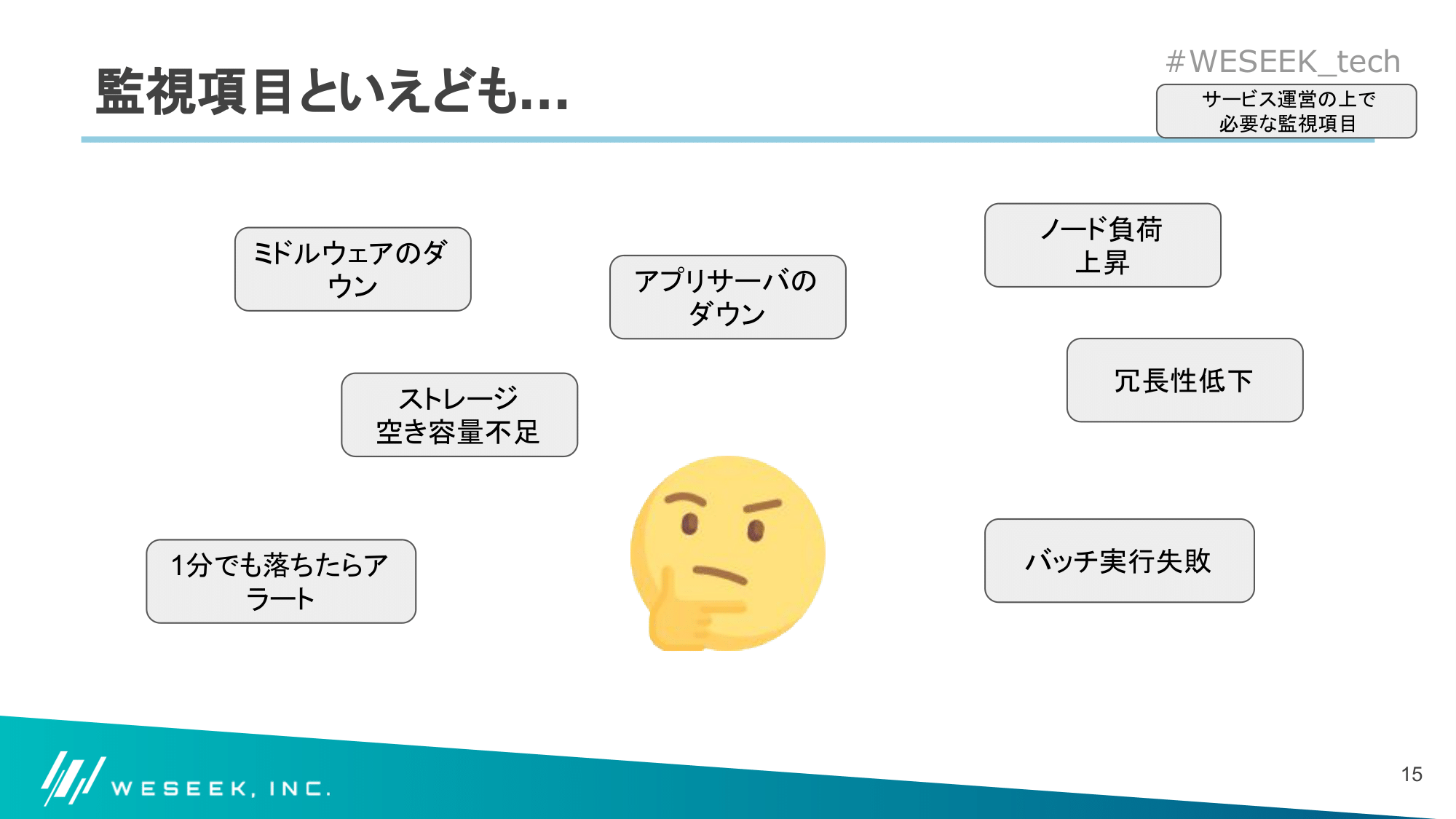
闇雲にアラートを出すと
- アラートの絶対量が人間の対応できる範囲を超える
- アラートばかりで寝られない
- そこまで重大じゃないと思われるアラートで起こされる
- そのアラートはホントに顧客サービスに直接影響するのか?
- 直接影響しないものもアラートとして出てしまう
- ほとんどスルーしてよいという認識になり、いずれ対応されなくなる
- 本当に対応しないといけないアラートが見逃される
- アラートばかりで寝られない
- 運用者は人間
- 人間が対応できる範囲のアラート量に調整する必要がある
サービスの運用者が正しく対応できるようにするための監視・アラートが、必要なときに対応されなかったり、運用者の負担だけを増大化する要因にしてしまいます。
SRE の考え方
上記のような事態を避けるために、SRE という概念が作り出されました。
- Site Reliability Engineering
- Google が提唱したエンジニアの役割
- システムの信頼性に焦点を置いている
- 可用性 がシステム運用における成功の前提条件になっている
- 以下の用語が定義されている
- SLO (サービスレベル目標/Service Level Objective)
- サービスレベルの目標値(ex. 99.9%)
- SLA (サービスレベル契約/Service Level Agreement)
- 一定期間で SLO 以上のレベルを満たすことが、利用者との契約に含まれる値
- SLI (サービスレベル指標/Service Level Indicator)
- システムの監視項目が成功した頻度
- SLO を下回る場合は何かしらの処置が必要
- SLO (サービスレベル目標/Service Level Objective)
可用性とは
では、成功の前提条件になっている可用性とは、どういう定義なのでしょうか。[1]
可用性(Availability)とは、システムを障害(機器やパーツの故障・災害・アクシデントなど)で停止させることなく稼働し続けること、またはその指標のことをいいます。
長い時間、システムを稼働し続けられることを高可用性(High Availability)ともいいます。
今回の文脈で使われる可用性は、「システムを障害で停止させることなく稼働させるための指標」という意味で捉えられそうですね。
運用で守るべきこと
SRE の考え方に沿うと、サービス運用上守るべき事項は以下にまとめられます。
- 顧客に提供しているサービスが SLO 以上で正常に稼働していること
- = 可用性を SLO に保つ
- サービスの裏側で動くミドルウェアの状態が、必ずしも直接顧客サービスに影響するとは限らない
- ex.) 縮退状態でもサービスは動く(その為の冗長化)
- SLO 値を算出するために SLI を定義する必要がある
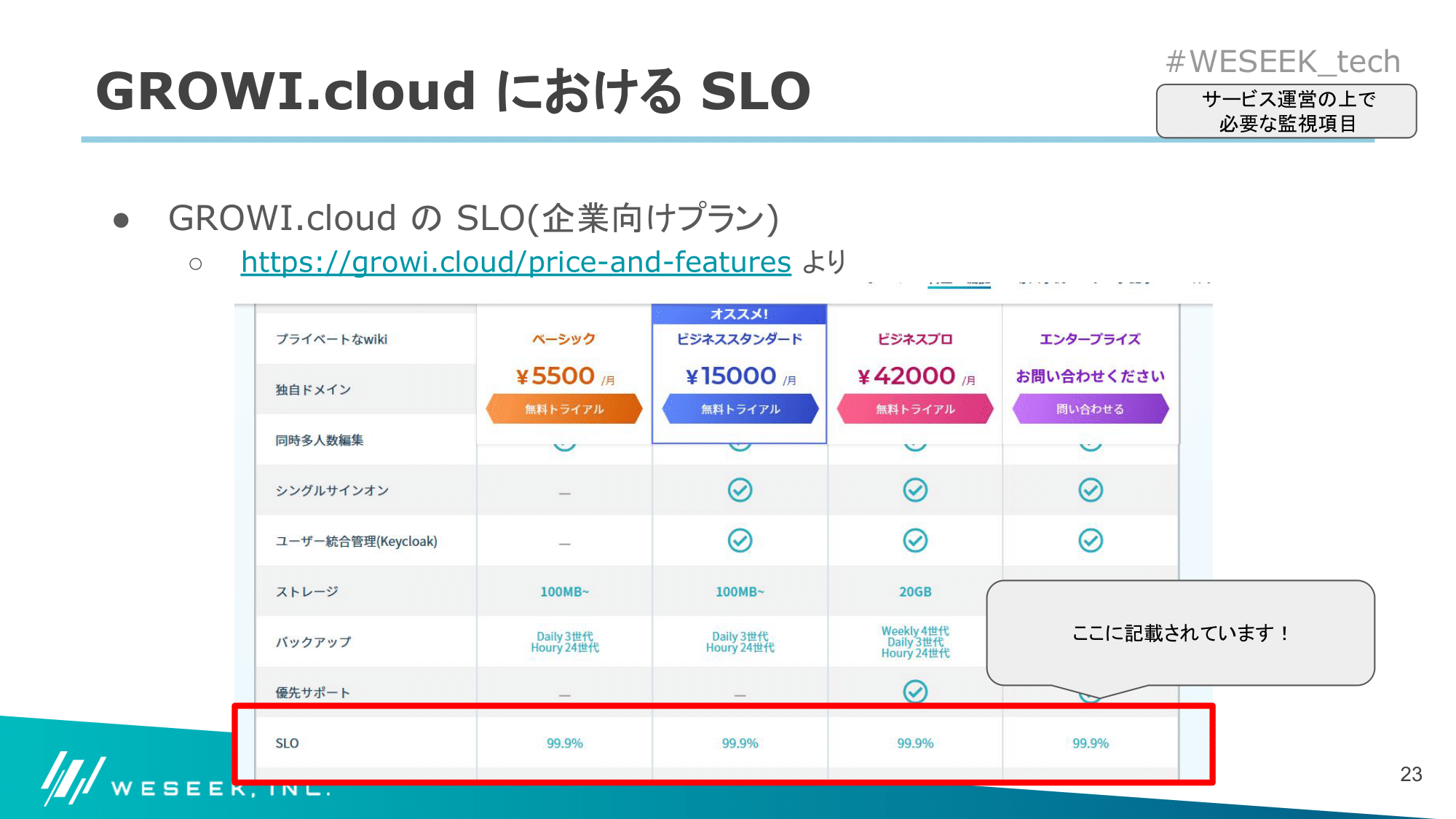
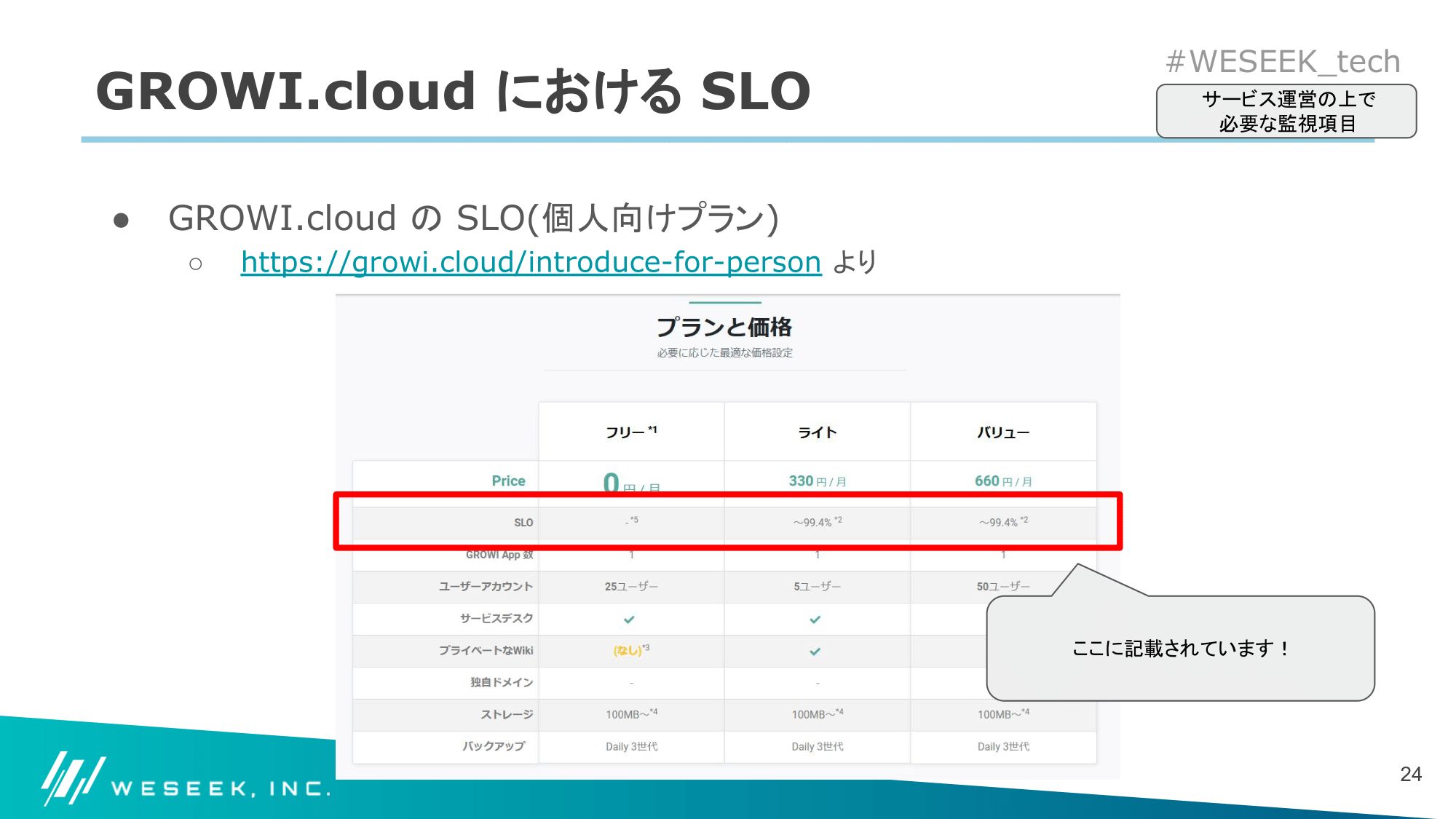
GROWI.cloud における SLO
- GROWI.cloud ではプランごとに 99.4% or 99.9% と設定
- Closed β での稼働状況を見つつ、正式リリース時に決定した
- GCE プリエンプティブルインスタンスを利用したプランでは、24 時間以内に必ず再起動する
- WESEEK Tech Conference #2 で発表も行っています
- コスト7割減!Kubernetes本番サービス環境の運用ノウハウ
- 以下の表を参考に、再起動にかかる時間を考慮し、99.4% という値を設定した
参考) 各 SLO における許容される down 時間
| SLO\期間 | 1日 | 1か月(30日) | 1年(365日) |
|---|---|---|---|
| 99.4% | 8分38秒 | 約4時間20分 | 約52時間半 |
| 99.9% | 1分26秒 | 約43分 | 約8時間45分 |
GROWI.cloud 上での SLO 表記
GROWI.cloud では、法人プラン/個人プランそれぞれで、各プランにおける SLO を公開しています。
SLO を運用者/利用者で共有することによって、サービスレベルの認識がお互いに合わせられるように努めています。
GROWI.cloud における SLI
GROWI.cloud 上の GROWI については、以下のような構成で稼働しています。
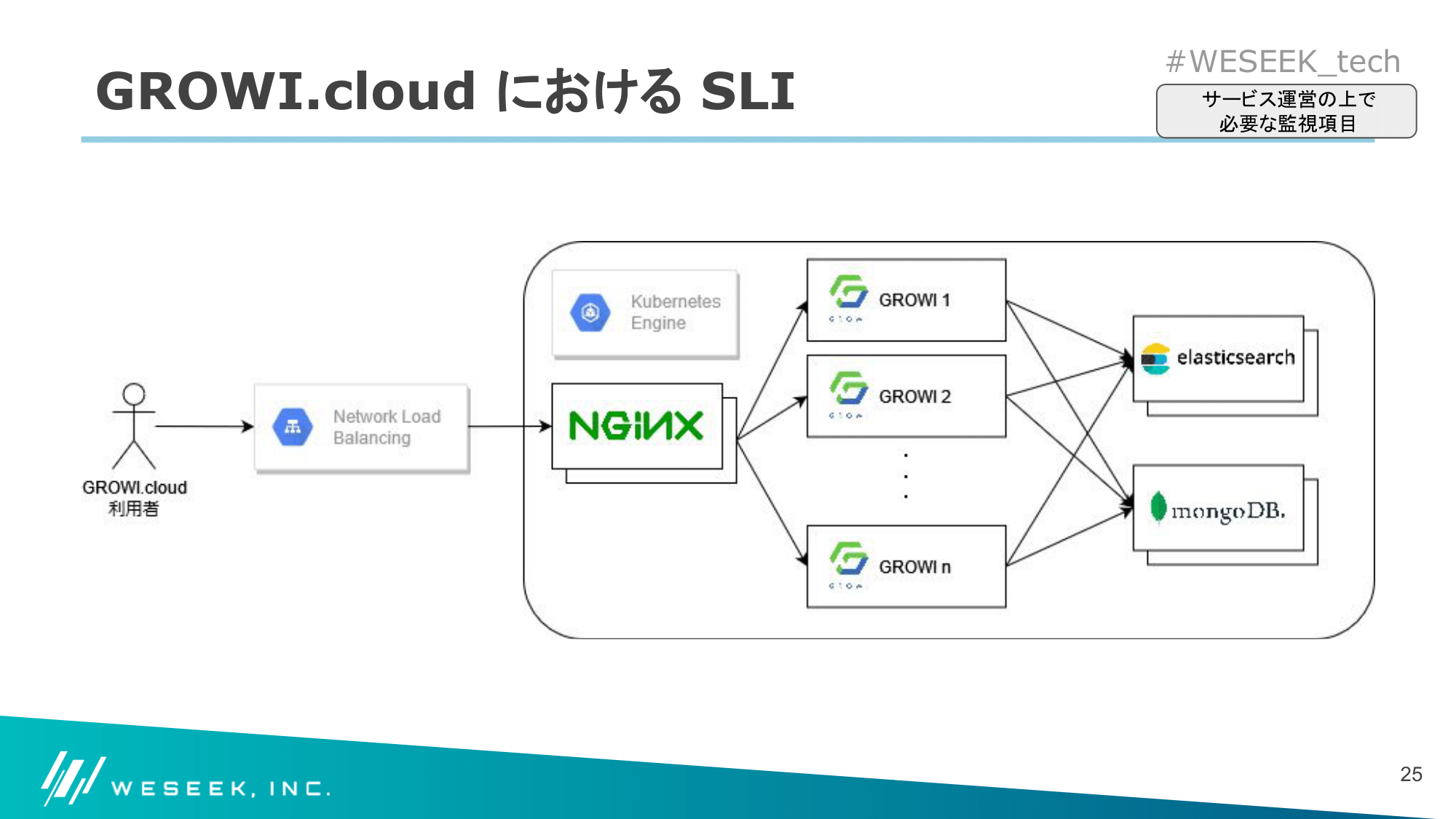
GROWI.cloud 構成図
SLO を目指すために必要な指標である SLI については、構成図のうち以下の部分から取得できる値を利用しています。
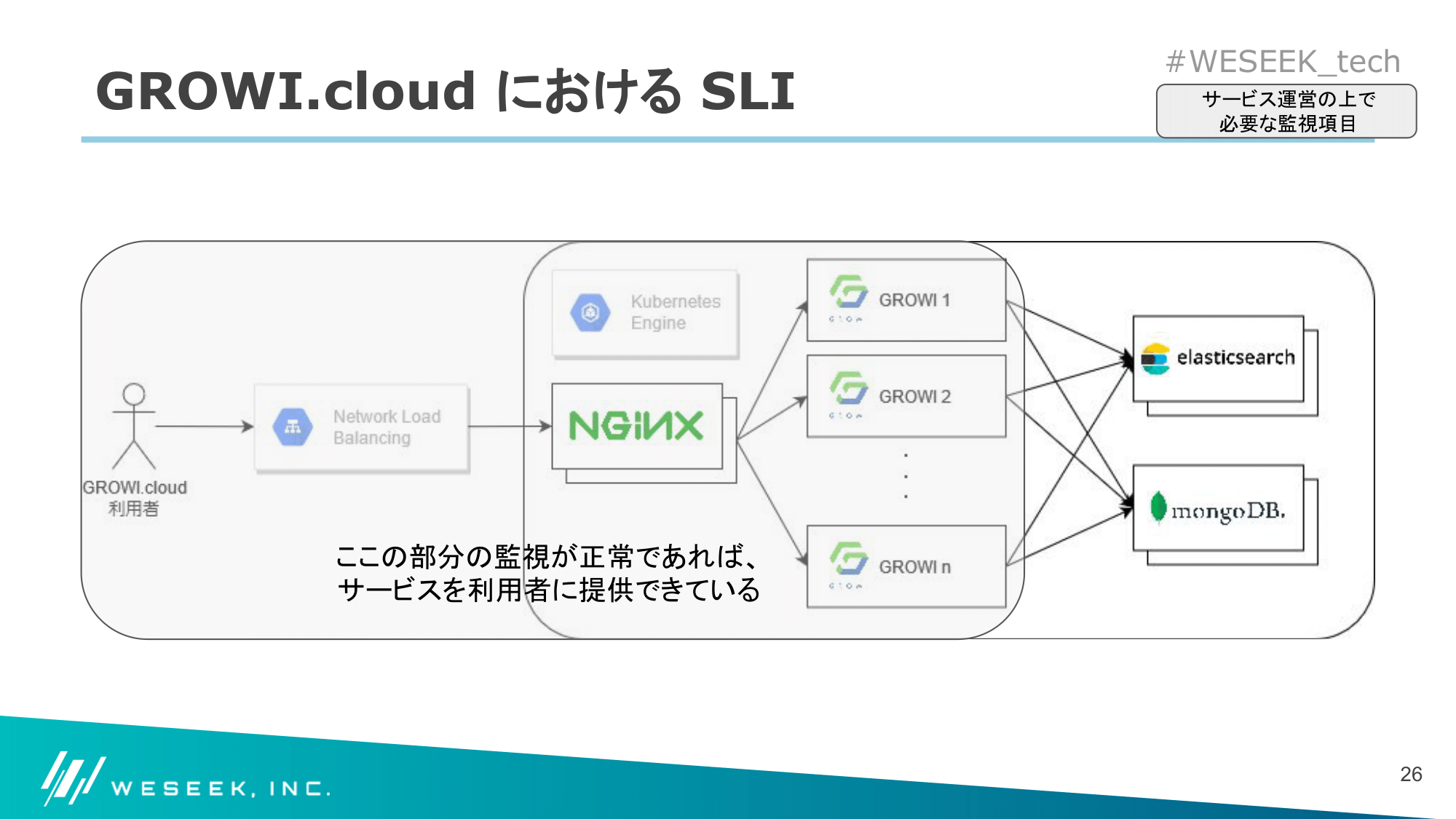
GROWI.cloud 上の SLI 関係部分
まとめ
1章では、SRE の考え方を用い、GROWI.cloud 上での運用方法を考えていきました。
- サービス運用で守るべきこと
- = 顧客がサービスを使える状態であること
- = 可用性を維持すること
- ≠ サービス提供に必要なシステム全てが、完璧な状態で稼働していること
- 可用性の指標
- SLO
- サービスレベルの目標値
- SLI
- 監視項目が成功した頻度
- SLO
- 可用性の指標を運用に乗せれば、うまくいきそう
2章: サービスの可用性を計測・可視化する手法
1章で制定した SLO/SLI といった指標を活用した運用体制を整えるため、2章では、
- 継続的に SLI を計測できているか?
- 継続的に SLO を達成できているか?
という点について、すぐに確認できるような環境を整備する手法をご紹介しました。
可用性の計測・可視化に必要な実施項目
準備が必要となる項目は以下の 2 点です。
- 監視・可視化ツールの選択
- 監視ダッシュボードの作成
- 何をどのように可視化するかを決める
- システム全体と個別のコンポーネント、それぞれのカットで見られる状態が望ましい
ゴールは、「サービス運営に必要な SLI を簡単に確認できること」です。
導入時の前提
GROWI.cloud での導入時の構成は以下の通りでした。

監視・可視化ツールの選択
監視・可視化ツールの候補は、当初以下のようなソフトウェア/サービスが挙げられました。

しかし、マネージドサービスについては、ノード数/コンテナ数による課金体系であったことから、当初から費用をかけたくないという希望と合致せずに、候補から外れました。
GROWI.cloud の事例
GROWI.cloud では、上記の候補のうち「Prometheus」を選択しました。
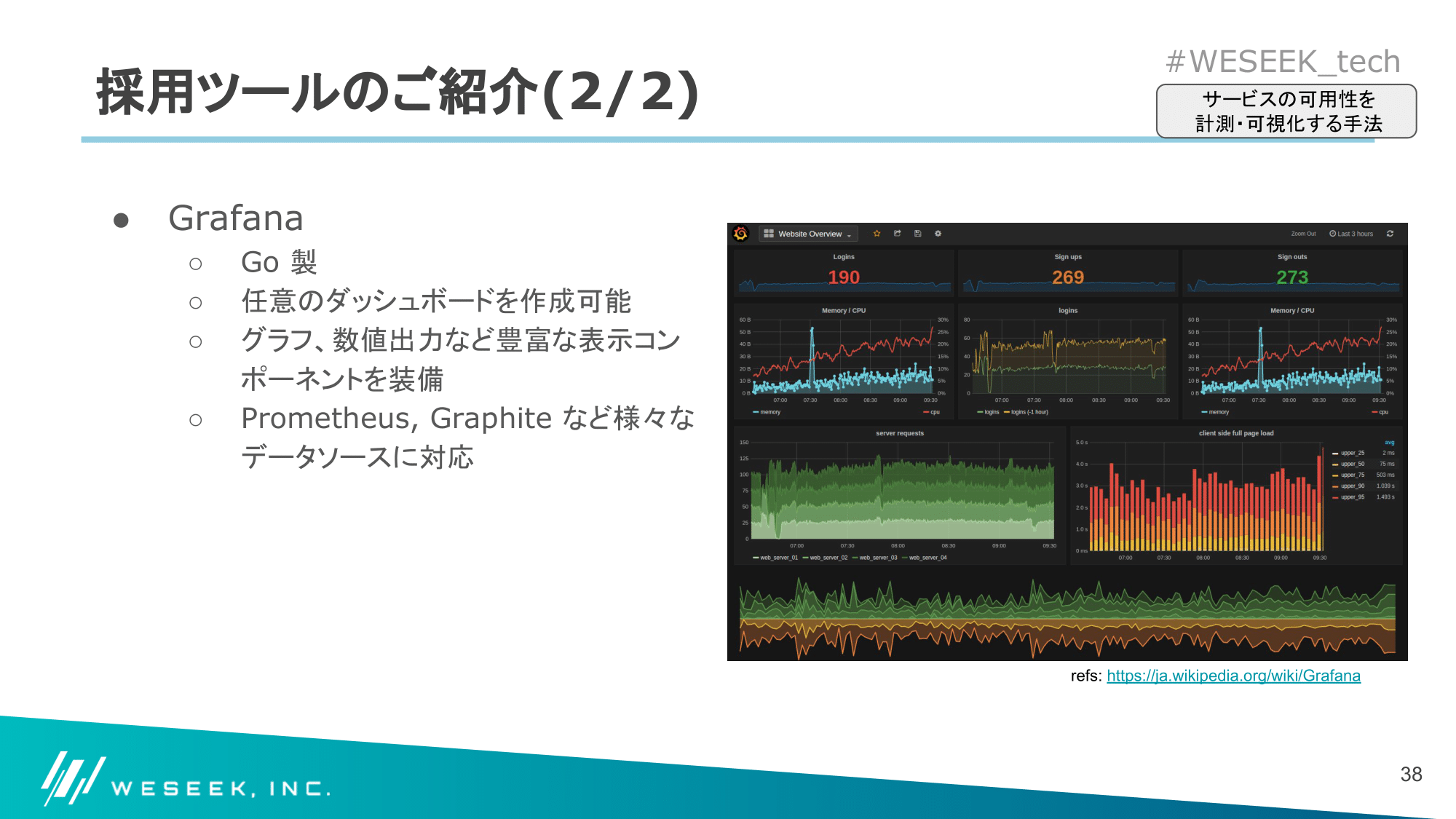
また、可視化には Prometheus をサポートしている Grafana を選択しました。
選択理由は以下の通りです。
- Cloud Native 界隈で話題になっていたから
- GROWI.cloud が載っている Kubernetes と相性がよさそうだったから
- Service Discovery 機構がついていたから
- プロセスの再起動をすることなく、動的に監視ターゲットを増やせる
- デプロイ手法が整備されていた
- helm chart(Kubernetes 上にリソースをデプロイするためのマニフェストパッケージ) が既にあった
- Service Discovery 機構がついていたから
- exporter を増やすことで任意のメトリックを溜め、アラートを出すことができるから
採用ツールのご紹介
GROWI.cloud へ導入したツールについて簡単にご紹介しました。
Prometheus
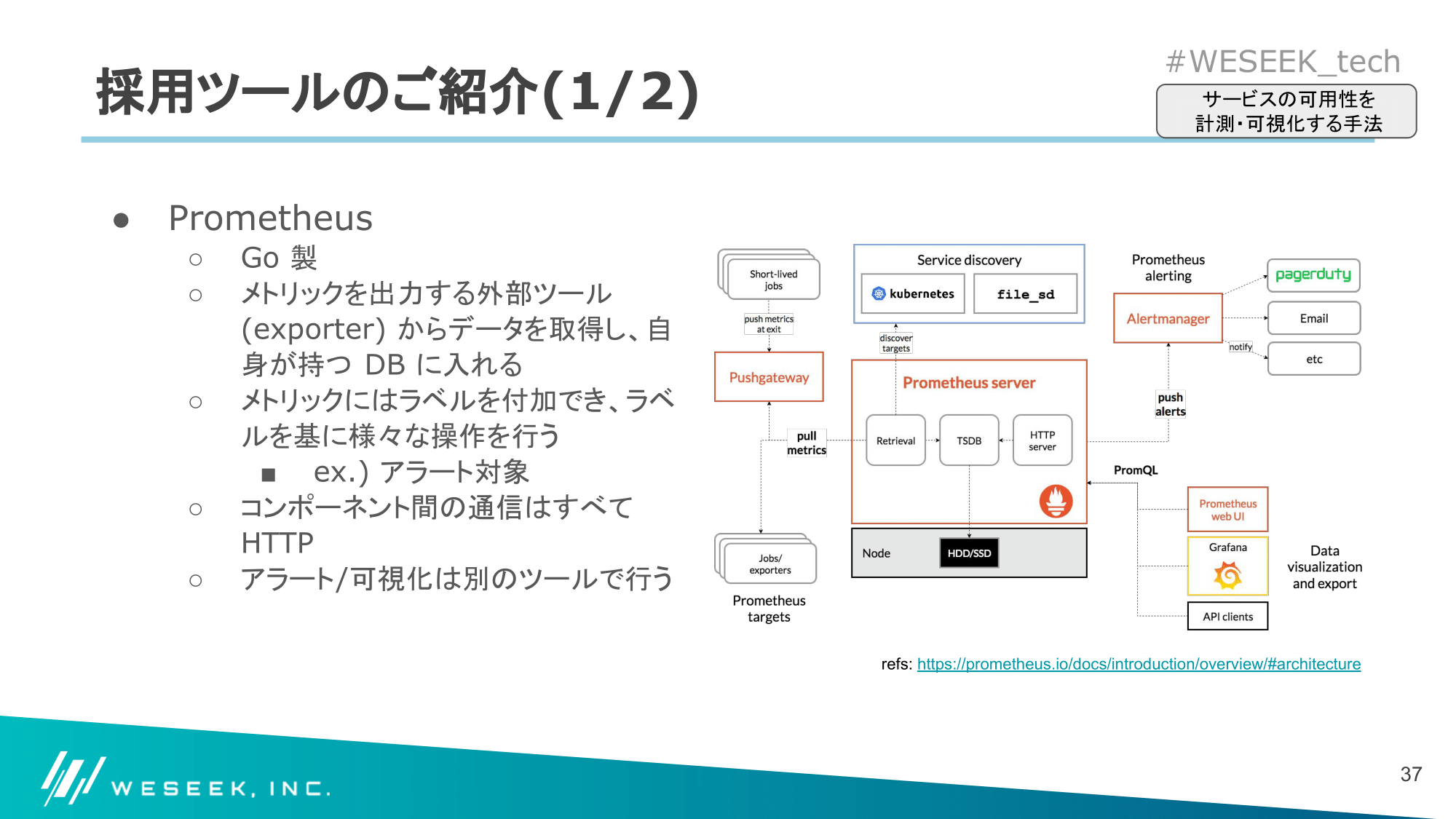
Grafana
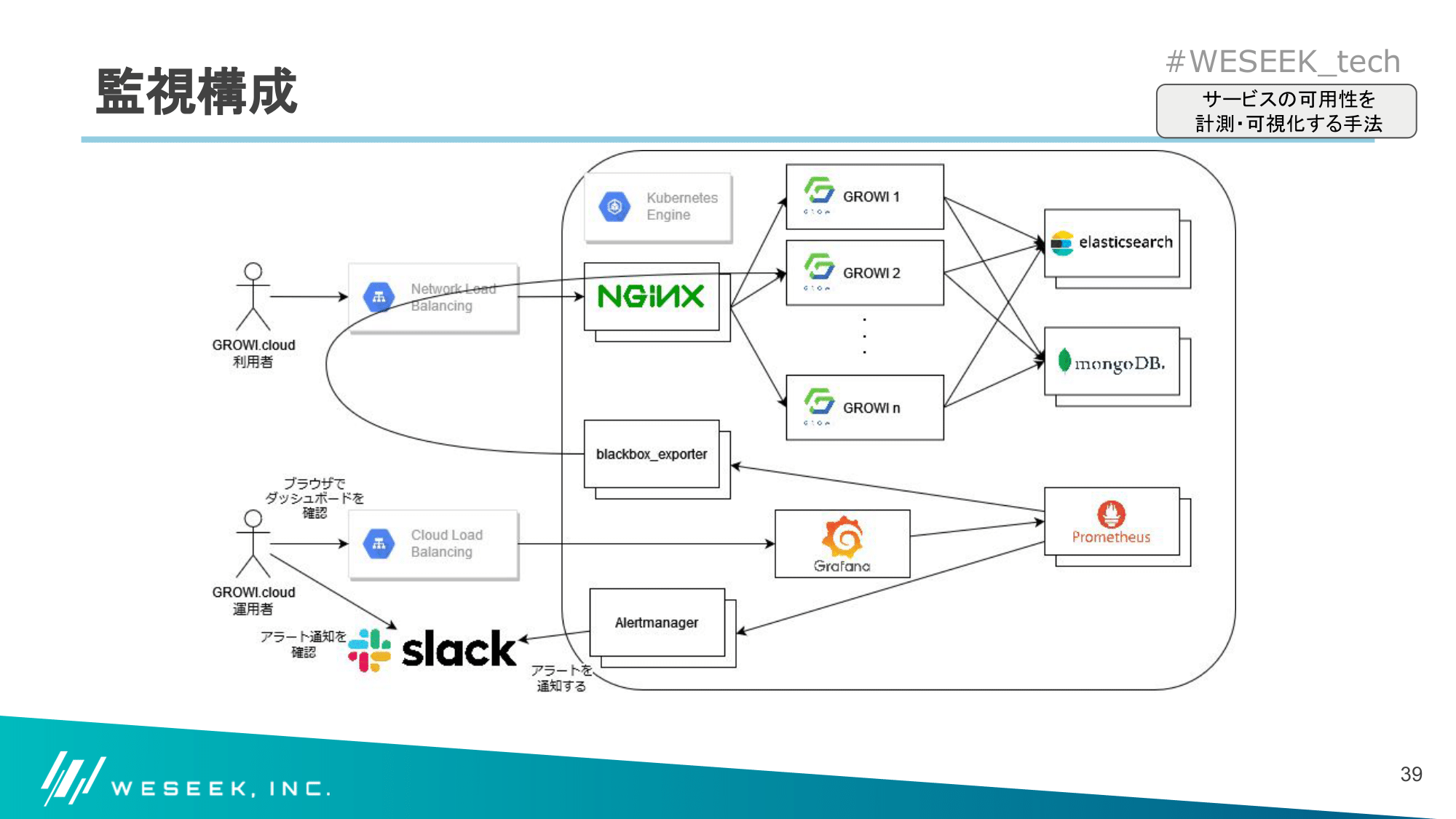
監視構成
GROWI が稼働している同一クラスタに監視/可視化ツールを加え、以下のように監視を実施することにしました。
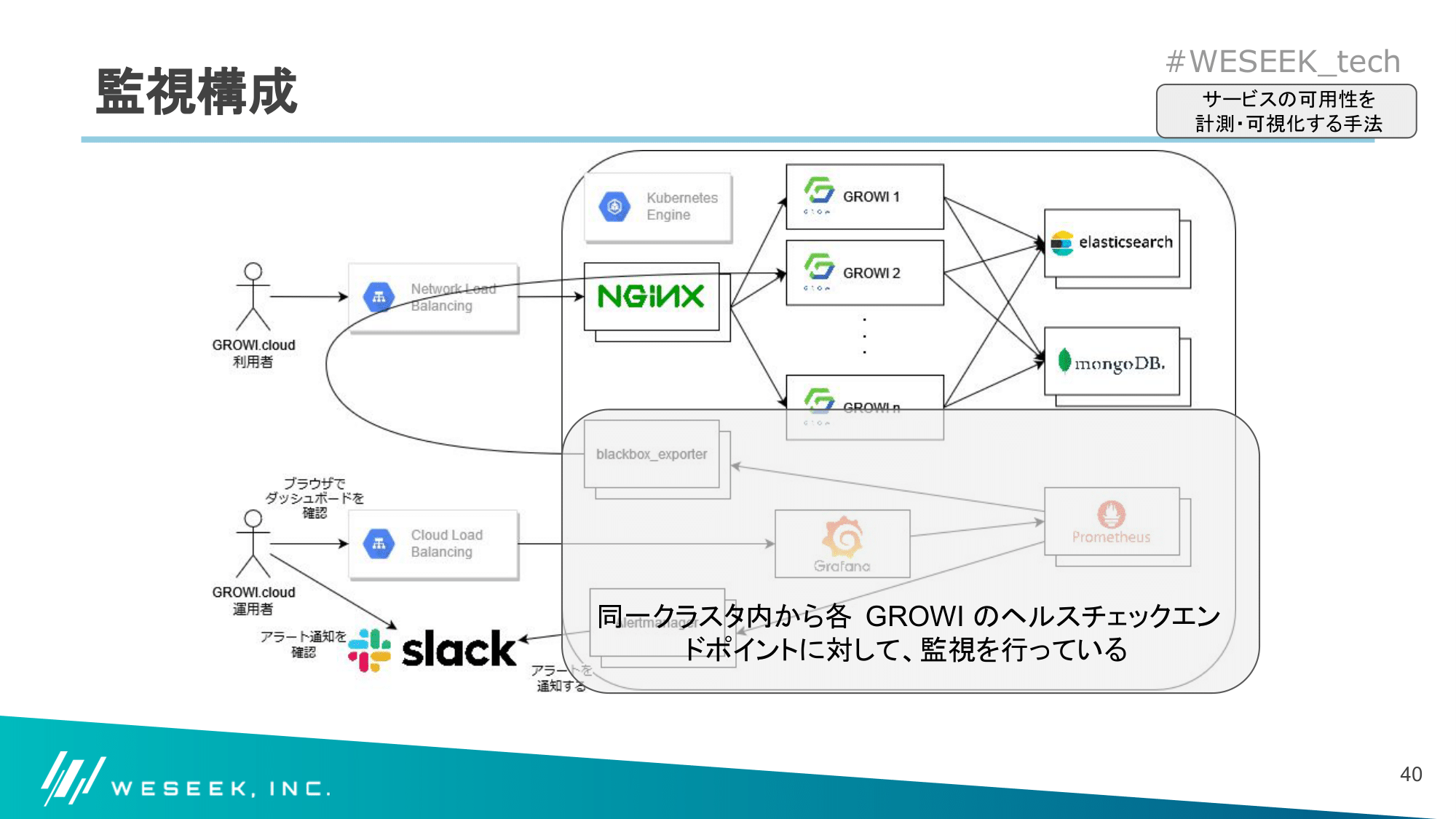
GROWI.cloud 上での可視化例
GROWI.cloud では、以下のような可視化のためのダッシュボードを用意しています。
システム全体の情報
こちらのダッシュボードでは、システム全体を俯瞰してすぐに確認できるような情報を表示しています。
以下は表示している項目の一例です。
- 過去 30 日間の SLI 値
- ノードタイプごとに分離して出力している
- インストール GROWI 数
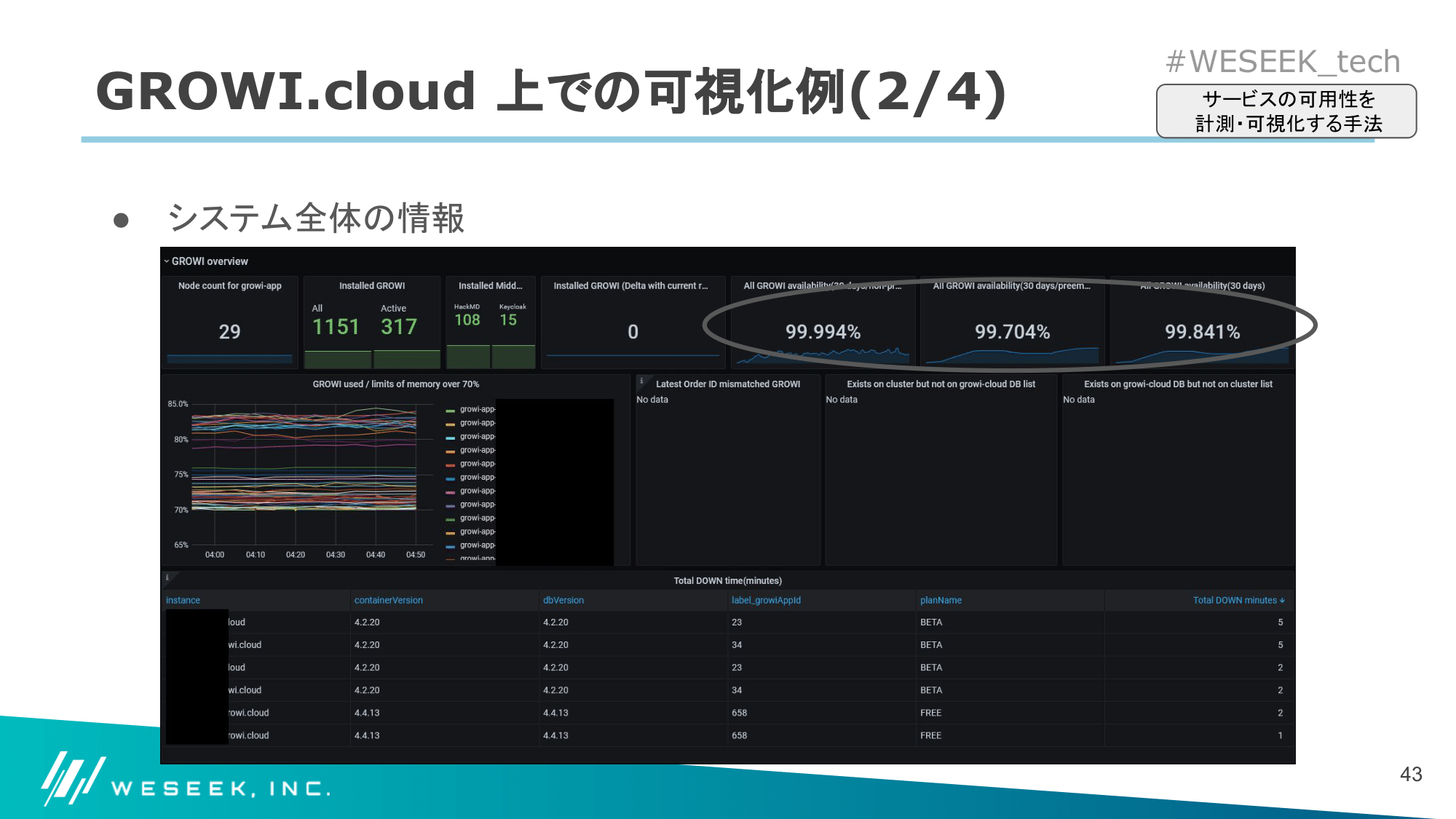
右上の赤丸部分に、1. の項目が表示されています。
個別コンポーネントの情報
こちらのダッシュボードでは、各アプリ単位でより細かい指標が確認できるような情報を表示しています。
以下は表示している項目の一例です。
- 各 GROWI ごとの SLI 値、許容される残り down 時間
- ミドルウェア情報(CPU/メモリ使用量/コネクション数など)
- ノード情報(CPU/メモリ使用量など)

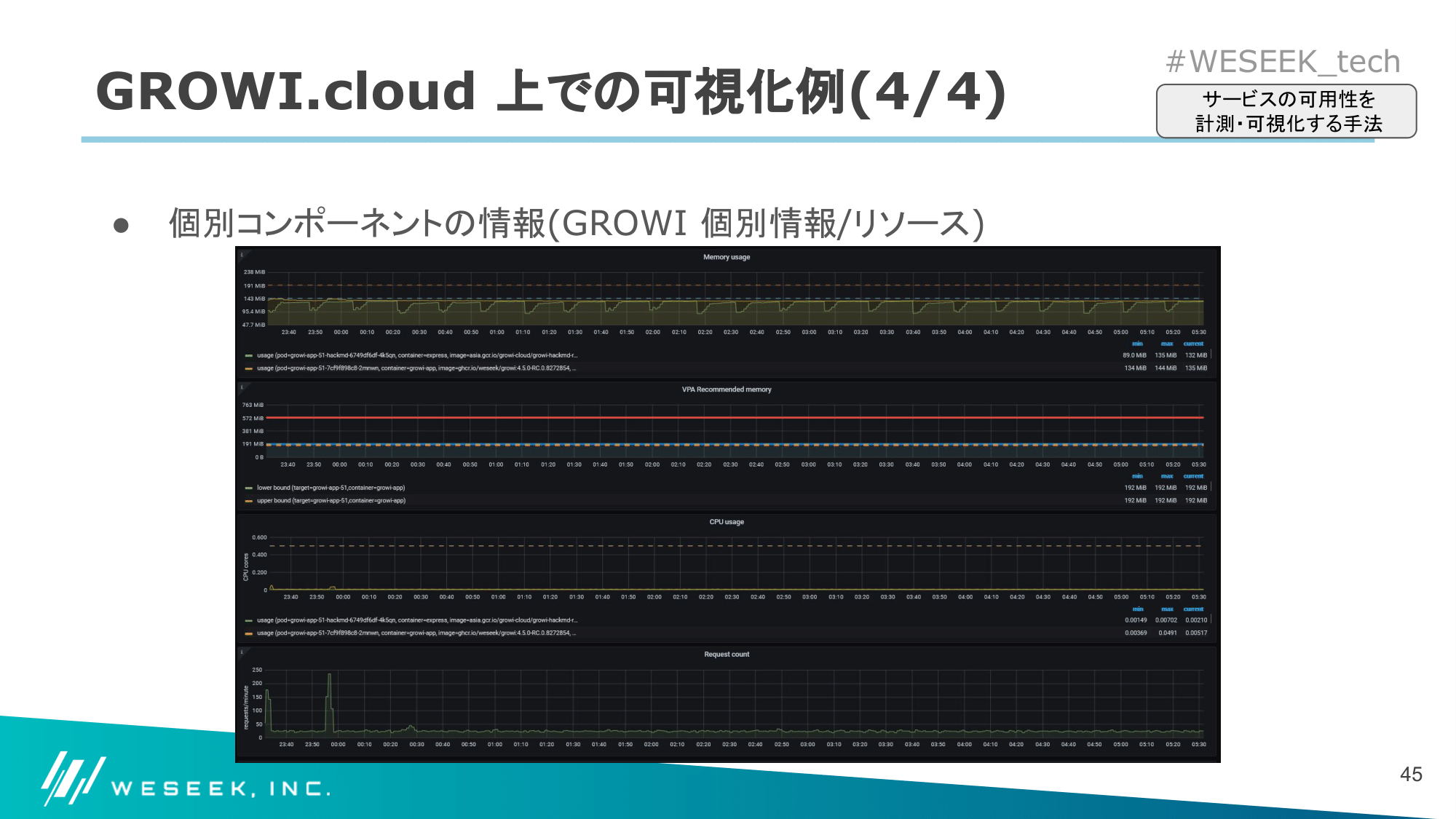
上記は、1. の各 GROWI に関する詳細情報の表示例となっています。
まとめ
2章では、1章で制定した SLO/SLI を継続的に確認できるような環境を整備し、どのような構成に至ったのか、どのように確認しているか、についてご紹介しました。
- 環境整備に必要な実施事項
- 監視・可視化ツールの選択
- 監視ダッシュボードの作成
- GROWI.cloud では以下の構成で監視を実施している
- Prometheus/Grafana を選択
- 全 GROWI / 各 GROWI に関する SLI の値を確認できるようにダッシュボードを用意
- GROWI が再起動してしまった原因を探りやすくするために、以下のようなグラフも併せて用意している
- メモリ/CPU使用率
- リクエスト数、等
3章: 可用性を維持/向上するために必要な取り組み
3章では、1章、2章でここまで揃えた情報を使い、実際にどのような取り組みを実施しているかについてご紹介しました。
可用性を維持するためには
SLI を SLO 以上に維持できるように意識し、対応する
- これに限ります
- GROWI down が発生した場合は、すぐに様子を見る
- ex.) SLO を下回りそうな GROWI については早急に何らかの対策を講じる
- いずれ障害になるであろう事象に、前もって対応する
- ex.) ミドルウェアのストレージ容量減少、冗長性低下
- これらの対応に必要な情報が、一目でわかるようなアラートを設定する
アラート対応例
アラート対応の一例です。
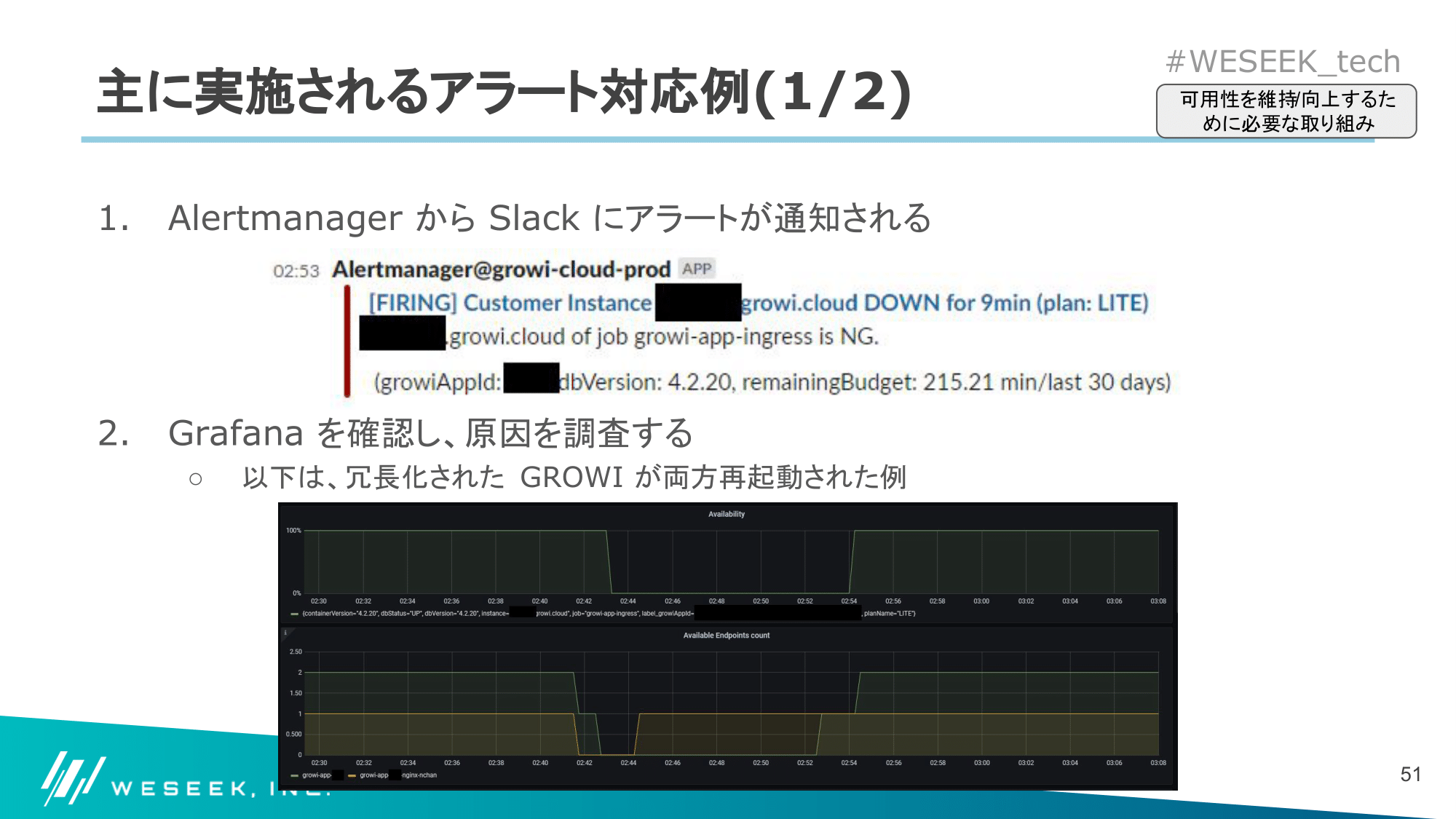

アラート対応時に見ているもの
先述した Prometheus/Grafana をフル活用しています。
アラートも、運用上 SLO/SLI をすぐ意識できるように、以下のような思想で設定しています。
- アラートも Prometheus 上のメトリックをベースに出している
- アラートには、当該の GROWI で SLO を達成するための許容される残りダウン時間も記載している
- 一目で GROWI がどういう状態なのかを把握できるようにするための情報を出している
可用性を向上するためには
GROWI.cloud では、可用性を向上するために、以下の 2 点を実施しています。
- 可用性の値を逐次気にして、可用性を高められる箇所がないか探し、対処する
- 「Availability 向上施策」と銘打って、集中的に行った時期もあった
- 障害対応履歴を残す
Availability 向上施策実例
- プリエンプティブルノードを利用したプランでの冗長化を実施
- ライト、バリュープラン
- リリース当初は、プリエンプティブルノードに 1 GROWI しか乗せていなかったが、99.4% の SLO を保てなかった
- 施策実施前 SLI: 99.00%
- 施策実施後 SLI: 99.93%
障害対応履歴を残す
- 障害発生時に、振り返れるように経緯を残すのが大切
- 記録は重要!
- 対応者以外にも障害内容を伝えられる
- 週次でチーム全体に報告し、対策内容について検討、実施へ繋げている
- 有識者の知見を借りられる
- 今後、似たような障害が起きないように、正しい対策を打てる
- 対応後に、改めて監視で収集したデータと突き合せ、より効果的な対策へ
- 今後、似たような障害が起きた時に、自分が/他の人が参考にできる
- 自分が忘れないため
- 対応者以外にも障害内容を伝えられる
まとめ
本発表のまとめです。
- サービス運営の上で必要な監視項目とは
- 真に監視するべきものは何かを洗い出す
- SLO を設定する
- サービスの可用性を計測・可視化する手法
- SLI を算出できるメトリックを整備する
- SLI を簡単に確認できるような環境を整備する
- ex.) ダッシュボードを整備する、アラート内容に記載する、等
- 可用性を維持/向上するために必要な取り組み
- 対応時は、1./2. で整備したものをフル活用
- 対応後は、対応内容を残してチームに共有
- 継続的に SLI を改善できるような動きへ
今後の GROWI.cloud 運用展望
- GROWI 上で実際に利用されるリクエストのエラー率で SLO を決定できるようにしたい
- 現状は、ヘルスチェックエンドポイントへの監視成功/失敗で判定している
- より利用者目線に立った監視ができるようになる
著者プロフィール
株式会社WESEEK / バックエンドエンジニア
2013年にWESEEKに入社。
node.js/Kubernetes を中心としたインフラ/アプリの設計・構築・運用に携わる。
GROWI.cloud の運用にリリース当初(2018~)より従事。
株式会社WESEEKについて
株式会社WESEEKは、システム開発のプロフェッショナル集団です。
【現在の主な事業】
- 通信大手企業の業務フロー自動化プロジェクト
- ソーシャルゲームの受託開発
- 自社発オープンソースプロダクト「GROWI」「GROWI.cloud」の開発
GROWI
GROWIは、Markdown記法でページを記述できるオープンソースのWikiシステムです。
GROWI.cloud
GROWI.cloudはOSSのGROWIを専門的知識がなくても簡単に運用・管理できる、法人・個人向けの商用サービスです。
大手SIer・ISPや中小企業、大学の研究室など様々な場所でご利用いただいております。
【主な特徴】
- テキストも図表もどんどん書ける、強力な編集機能
- チーム拡大に迅速に対応できる管理者向け機能を提供
- 充実した機能・サポートでエンタープライズにも対応
【導入事例記事】
インターネットマルチフィード株式会社様
[https://growi.cloud/interviews/mfeed/?utm_source=connpass-top&utm_medium=web-site&utm_campaign=mf:embed:cite]
株式会社HIKKY(VR法人HIKKY)様
[https://growi.cloud/interviews/hikky:embed:cite]
WESEEK Tech Conference
WESEEK Tech Conferenceは、株式会社WESEEKが主催するエンジニア向けの勉強会です。
WESEEKに所属するエンジニアが様々なテーマで発表を行う予定です。
次回は、1/27(木) 19:00~20:00に開催予定です。
GROWI と連携できる GROWI bot の開発を通じて学んだ「Slack社が却下するシステムの作り方」そして「Slack社が譲れない仕様」についてお話します。
現在、connpassやTECH PLAYで参加受付中です。皆様のご参加をお待ちしております!
https://weseek.connpass.com/event/234368/
TECH PLAYはこちらから
一緒に働く仲間を募集しています
東京の高田馬場オフィス、大分にある別府サテライトオフィスにてエンジニアを募集しております。
中途採用だけではなく、インターンシップも積極的に受け入れています!
詳しい募集要項は、弊社HPの採用ページからご確認ください。

